Visual pattern recognition in 1955
Reading through the proceedings of "the session on learning machines", in the "1955 western joint computer conference"

[this is an expanded version of a thread I posted on Twitter on 24.01.23]
Here’s a paper from 1955 that basically suggests the use of what we would today call a hierarchical convolutional processing for visual pattern recognition tasks. This is ~7 years before Hubel and Wiesel’s feed-forward model of simple cells, ~20 years before Fukushima’s Neocognitron, and about ~30 years before LeCun’s CNNs. The “filters” here were hand-designed, rather than learned (though see more on that in the end). Much of the background, intuition, and the problem formulation itself remains completely relevant today.
The paper was part of the session on learning machines in the 1955 western joint computer conference. The signed author is Gerald Dinneen, but the text makes it clear that this work was done by him together with Oliver Selfridge. Both were at the Lincoln Laboratory in MIT. Indeed in the same proceedings the previous article is by Selfridge, describing the approach for Pattern Recognition more generally.
The whole thing is worthwhile having a look at. I will quote some key paragraphs, mostly from Dinneen and some from Selfridge, and add minimal commentary.
Pattern recognition
According to Selfridge:
By pattern recognition we mean the extraction of the significant features from a background of irrelevant detail.
First, Dinneen explain a main reason that this problem is challenging:
Consider, for example, how many different representations of the block capital A we recognize as A. A great number of variations in such things as orientation, thickness, and size can occur without loss of identity. Our real live problem then is to design a machine which will recognize patterns. We shall call any possible visual image, no matter how cluttered or indistinct, a configuration. A pattern is an equivalence class consisting of all those configurations which cause the same output in the machine.
Then, they present the key idea of a hierarchical processing by “a sequence of simple operations”:
Our theory of pattern recognition is that it is possible to reduce by means of a sequence of simple operations a configuration to a single number, or by means of a set of such sequences to a set of numbers. We believe that for the proper sequences, almost all of the configurations belonging to a given pattern reduce to the same number or set of numbers.
Before specifying what kind of “simple operations” those might be, the paper describes the overall architecture and how to simulate it on a digital computer. Note the word “simulate” here. Indeed, it seems that they thought of the digital computer as a tool to simulate the principles according to which a different kind of machine would work, one that is better suited for dealing with such problems. This topic deserves its own short post, hopefully to be written, for now I’ll leave it with another quote from Dinneen (emphasis in origin):
The problem we have stated is not basically arithmetic, and it is not even clear that a machine for pattern recognition should be completely digital. However, one of the very important applications of a high-speed digital computer is the simulation of just such problems.
Overall architecture
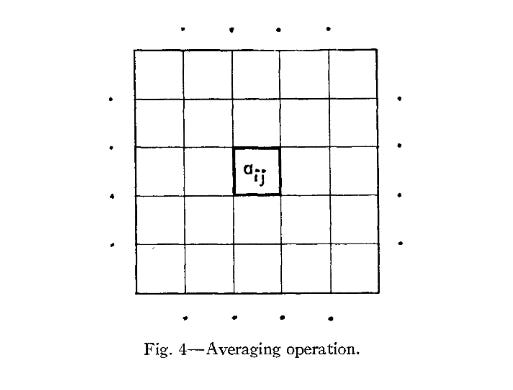
The architecture itself was built to handle binary (1 for black, 0 for white) images of size 90*90 (which was chosen “to be as large as was practical in terms of computer storage”). There were 3 “stores” of such images. First there is the “working image” currently being transformed. The result of such transformation is another image, stored in the “new image”. This new image could then be loaded back into the “working image” store “if a sequence of operations is to be performed”. In addition, there was a special store for the original image (which is also the input image at the beginning), in case it had to be stored throughout:

The paper discusses (in some length) two kind of operations on images. Both are a “linear non-linear” type of operation: specifically, some convolution followed by thresholding.
The “Averaging” and “Edging” operations
The first one is an “Averaging Operation” for which the convolution part is basically a low-pass filter, smoothing the image. The “kernel size” is taken to be 5*5.

In the paper, there are many visual examples1 for what this transformation does to images, as a function of the threshold parameter. Here’s just one:

Another version of the operation is also mentioned in which the threshold is set dynamically:
threshold for the small 5X5 window is determined by the degree of homogeneity inside a larger window, say 15X15. In particular, for each cell we count the number of ones inside a 15X15 window surrounding it and use this number to set the threshold for the 5X5 window. This is like an automatic gain control.
The second operation, maybe unsurprisingly, is some kind of a high-pass filter / edge-detector referred to here as an “Edging operation”. As the paper put it:
The edging operation, quite unlike the averaging operation, preserves elements which are centers of asymmetry, that is, those which are located in the regions of discontinuity of the image. The operation sharpens differences. It picks out the edges of letters and for certain choices of thresholds locates the corners, junctions, and end points of letters […]
The edging operation is like a two-dimensional derivative, since we count changes about the center element.
There are some details of how the threshold is set (relative to the overall “intensity” in the patch) and again many visual examples. Here’s just one:

Why these operations?
The smoothing and derivative-filter operations both look very natural today, but this might not have been the case in those early days of digital visual processing. The paper doesn’t justify these as some ‘well known’ thing either. Rather:
We tried to pick operations which were simple in structure and unrelated to particular patterns. In other words, we avoided special operations which might work very well for A's and O's, but not very well for other shapes. There is evidence in neurophysiology, moreover, that both averaging and edging of visual images are performed by the nervous system of many animals.
I find the neurophysiology comment particularly intriguing. Again, this is before H&W discovery of the “simple cell” in the cat visual cortex. There’s no reference here, so it’s hard to say what Dinneen had in mind, but we can consult the commentary piece on that session, in the same proceedings, by no else than Walter Pitts. Pitts seems to be suggesting that the “edging” and “averaging” operations relate to the the on-center/off-surround and off-center/on-surround ganglion cells in the retina, discovered by Kuffler (in the early 50’s). I suspect that early works by Hartline on lateral inhibition2, also in the retina, are another possible candidate (at least for an edge-detector like mechanism). Pitts does not mention those explicitly, but seem to hint on that direction as well.
Finally, I can’t help but quote also this paragraph just to appreciate the heroic effort of programming all of this with the technology of the time:
Although the first two operations are very simple, the coding of the program is quite complicated. This is due to a large extent to the necessity of using the individual bits of the storage registers as independent storage bins. We need a lot of shifting and cycling; the simple averaging operation takes about 300 instructions and requires about 20 seconds a letter. The two window averaging takes about 400 instructions and requires about 4 minutes. The edging requires 700 registers of instructions and takes 2 minutes.
And speaking of programming, the acknowledgment section of the paper is a testimony for the lab reality, and who actually programmed and operated the computers back then:
It would have been impossible to obtain the experimental results without the excellent assistance of Miss B. Jensen and Mrs. M. Kannel in programming, coding, and operating the Memory Test Computer.
The “Learning” part
There isn’t much of machine learning in Dinneen’s report. But the issue and the need for some learning component was well recognized already. We can find the general approach outlined in the Selfridge’s paper (which serves as an introduction to the more specific report). The idea was how to learn a good sequences of operations (it seems to be assumed that the basic operations themselves were to be fixed or pre-given to the machine):
I shall now discuss our plans for having the computer itself hunt for good sequences and assign the proper values. Every sequence is good or bad according as the numbers obtained from applying it to images tend to differ consistently for different symbols.
The planned strategy is a neat description of Supervised Learning:
We now feed the machine A's and O's, telling the machine each time which letter it is. Beside each sequence under the two letters, the machine builds up distribution functions from the results of applying the sequences to the image. Now, since the sequences were chosen completely randomly, it may well be that most of the sequences have very flat distribution functions; that is, they have no information, and the sequences are therefore not significant. Let it discard these and pick some others. Sooner or later, however, some sequences will prove significant; that is, their distribution functions will peak up somewhere. What the machine does now is to build up new sequences like the significant ones. This is the important point. If it merely chose sequences at random it might take a very long while indeed to find the best sequences. But with some successful sequences, or partly successful ones, to guide it, we hope that the process will be much quicker.
I don’t actually know if Selfridge and Dinneen proceeded with that plan, and if so, how well it worked out. It would be nice to look this up sometime.
Few closing remarks
The proceedings of this “session on learning machines” is a fascinating documentation of the early days of the fields.
Reading Selfridge and Dinneen, it is very telling how their approach is rooted in ideas about signal processing, filtering, and “statistics”, rather than (formal) computation, logic, or “rules”. In the same proceedings, there is also a representative of the other approach: a work by Allen Newell on chess playing. This tension if of course a recurring theme ever since, but it’s interesting to see just how far back it goes, and how researchers back in the time already understood it to be important.
It is very common to attribute the intuition behind CNNs to the H&W model of the primary visual system. The Dinneen and Selfridge papers are a compelling argument that the basic idea might have been going around before that, and nontheless might have been inspired by some (perhaps more vague) intuition/analogy to biological vision, possibly at the retina level.
More generally, the complicated relationships of AI/ML with neuroscience and psychology are of course another recurring theme, which is not completely independent of the first one I mentioned. In the words of Walter Pitts, in the beginning of his commentary of that session:
The speakers this morning are all imitators in the sense that the poet in Aristotle "imitates" life. But, whereas Messrs. Farley, Clark, Selfridge, and Dinneen are imitating the nervous system, Mr. Newell prefers to imitate the hierarchy of final causes traditionally called the mind. It will come to the same thing in the end, no doubt
“It will come to the same thing in the end” — I guess we are still waiting on that.
Interestingly these are actual photographs taken of “one of the MTC scopes”. Apparently this prehistoric computer back in ‘55 (the Memory Test Computer, or MTC, in Lincoln Lab) had some kind of a graphical output interface that they could plot pictures on.
The idea that lateral inhibition can implement something similar to a derivative-filter / edge detector goes in fact all the way back to Ernst Mach, in the 19th century — way before any physiological evidence could have been presented to support it. It was Hartline (and later Barlow as well) who provided such physiological evidence.